
Quantum-inspired genetic algorithm for designing planar multilayer photonic structure

The Quantum Genetic Algorithm
In QGA, a quantum chromosome, composed of multiple qubits, represents a potential solution. This algorithm mimics the evolution of physical qubits undergoing quantum logic gates, where “qubits” and “quantum gates” refer to mathematical-quantum information and operators within the complex Hilbert space, respectively. The algorithm manipulates these chromosomes using quantum gates, analogous to genetic operations of crossover and mutation. Leveraging superposition, a quantum chromosome can represent multiple solutions simultaneously, vastly increasing the algorithm’s ability to explore a large search space. The use of quantum entanglement can introduce correlations between qubits, enabling the algorithm to maintain a higher diversity of solutions and avoid premature convergence on local optima. These characteristics make QGA particularly suitable for complex optimization problems where traditional genetic algorithms may struggle due to the sheer size of the search space or the need for rapid convergence46. In addition, the evolution of quantum chromosomes can save memories by avoiding maintaining groups of binary vectors in CGA, which represent the population in the generation. QGA also utilizes the concept of quantum entanglement, enabling a more effective exchange of information between solutions. This makes QGA more adept at avoiding premature convergence to local optima, which is a common pitfall in CGA. In the evolution of QGA, the quality of the quantum chromosome is evaluated by calculating the fitness values of independent measurements of the quantum chromosome (the details of quantum measurement are in the Method section). The fitness values are evaluated by a figure-of-merit (FOM), which is used to describe how close between a designed PML structure and the ideal TRC. The FOM can be calculated by:
$$FOM=\frac10\,\int _\!\lambda _1^\lambda _2\left(Tl\left(\lambda \right)-Tl_ideal\left(\lambda \right)\right)^2d\lambda \int _\!\lambda _1^\lambda _2S\left(\lambda \right)^2d\lambda $$
(1)
(the details of the FOM and parameters definition are in the Supplementary Information, Section 1). Minimizing the FOM will allow the designed TRC to approach the ideal TRC, so that the fitness value in the QGA is defined as f = −100 × FOM. The measurements with high fitness values provide genetic information for the evolution direction of quantum chromosomes.
Compared with the CGA, QGA employs the probability amplitudes of qubits to encode chromosomes (as depicted in Eq. 12) and utilizes quantum rotation gates to execute the chromosomal updated operations. Consequently, the formulation of the quantum rotation gates serves as a critical aspect of QGA, directly influencing the algorithm’s performance. Here, we apply rotation-Y (Ry) gates on each qubit in the chromosome to realize the evolution. The Ry gate can be defined in a matrix form as28,47,48:
$$Ry\left(\theta \right)=\left[\beginarraycc\cos \frac\theta 2 & -\sin \frac\theta 2\\ \sin \frac\theta 2 & \cos \frac\theta 2\endarray\right]\,$$
(2)
The updated process is:
$$\left[\beginarrayca_k^t+1\\ b_k^t+1\endarray\right]=Ry\left(\theta _k^t\right)\left[\beginarrayca_k^t\\ b_k^t\endarray\right]=\left[\beginarraycc\cos \frac\theta _k^t2 & -\sin \frac\theta _k^t2\\ \sin \frac\theta _k^t2 & \cos \frac\theta _k^t2\endarray\right]\left[\beginarrayca_k^t\\ b_k^t\endarray\right]$$
(3)
where \([\alpha_k^t+1, b_k^t+1]^\rmT\) and \([\alpha_k^t, b_k^t]^\rmT\) represent the probability amplitudes of the k-th qubit in the chromosome at the t + 1-th generation and the t-th generation, respectively. \(\theta_k^t\) is the rotating angle for the Ry gate. We used an adaptive adjustment strategy28 for the quantum rotation angle so that the direction and magnitude are updated dynamically during the evolutionary process. A large rotating angle is set early in the evolutionary process to quickly explore the solution space and find regions likely to contain optimal values. To accurately find the optimal value, we reduce the magnitude of rotating angle as evolution continues so that it eventually converges to a global optimum. The update of rotating angle follows the following formula:
$$\theta _i=\theta _\max -\left(\frac\theta _\max -\theta _\min N\right)\times i\,$$
(4)
where θi is the value of the rotating angle of the i-th generation, N is the max generation, θmax and θmin is the upper bound and lower bound of θ. The adjustment strategy of rotating angle is shown in Table 149.
In the CGA, the crossover operation in the evolution allows for an expansive exploration of the solution space. However, the quantum chromosome itself has the property of individual diversity resulting from quantum superposition. So, there is no need to perform the crossover operation in the QGA. On the other hand, mutation is the operation that can ensure sufficient variety in the population to avoid local optima, which is important for both CGA and QGA. Different from CGA, quantum mutation will appear on the quantum chromosome and completely reverse the individual’s evolutionary direction by swapping the value of probability amplitudes a and b of mutated qubits, which is implemented by X-Gate on the randomly selected qubits as47:
$$X=\left[\beginarraycc0 & 1\\ 1 & 0\endarray\right],\,X\left[\beginarrayca_k^t\\ b_k^t\endarray\right]=\left[\beginarraycb_k^t\\ a_k^t\endarray\right]\,$$
(5)
Additionally, at the start of each QGA iteration, the genetic information of the optimal individual obtained from the previous QGA iteration will be partially incorporated into the initialization of the quantum chromosome, which reinforces the retention and utilization of valuable genetic information, leading to more efficient convergence towards optimal solutions. Therefore, the initialization of the quantum chromosome q in iteration τ is:
$$q\left(\tau =0\right)=\left[Ry\left(\theta _k^rand\right)\,\cdot\, \left[\beginarrayc\frac1\sqrt2\\ \frac1\sqrt2\endarray\right]_k\textfor\,k=1,2,\ldots ,n\right]q\left(\tau\, >\, 0\right)=\left[w_p\,\cdot\, \left[\beginarrayca_k\\ b_k\endarray\right]^it-1+(1-w_p)\,\cdot\, Ry\left(\theta _k^rand\right)\,\cdot\, \left[\beginarrayc\frac1\sqrt2\\ \frac1\sqrt2\endarray\right]_k\textfor\,k=1,2,\ldots ,n\right]\,$$
(6)
where θrand is the randomly generated initial angle between 0 to π, wp is the weighing factor to balance the genetic information from prior QGA iteration and random initialization in the current iteration. Each qubit is firstly initialized to a uniform superposed state by the Hadamard gate as:
$$H=\frac1\sqrt2\left[\beginarraycc1 & 1\\ 1 & -1\endarray\right],\,H\left[\beginarrayc1\\ 0\endarray\right]=\left[\beginarrayc\frac1\sqrt2\\ \frac1\sqrt2\endarray\right]$$
(7)
Then, a series of Ry gates with randomly generated angles is applied to each qubit to produce a random quantum chromosome for QGA. Except for the first QGA iteration, other iterations will start with the initialized quantum chromosome which also incorporates the solution of former QGA iteration with weighing factor wp as shown in Eq. 6. The determination of wp is based on the following formula:
$$w_p=\frac12\fracbest_currentbest_all$$
(8)
where bestall and bestcurrent are the best fitness values of all time and in the current iteration, respectively. If the current iteration successfully converges to or exceed the fitness value of all time, bestall will equal to bestcurrent at the end of the iteration, so that wp = 0.5. Otherwise, bestall will be higher than bestcurrent at the end of the iteration, which means that the initialization of the next iteration will have higher degree of randomness to encourage exploration of the entire landscape.
Additionally, to further mitigate the risk of the algorithm falling into a local optimum, we introduce an operation which we call memory corruption. This operation allows the optimal result, inherited from the previous cycle, to be discarded with a certain probability. This ensures that the incoming iteration does not simply inherit the optimal solution from the previous one. Consequently, an observable decay of the best solution can occur during the evolution of QGA, preventing stagnation and encouraging the search for new potential solutions.
The evolution of the QGA will terminate at a pre-defined maximum generation. However, if the evolution remains stagnant for a long time, it will be considered to have reached a local optimum and thus will be terminated. The termination criteria can vary based on the specific optimization problem. For the optimization problem discussed in this paper, we have determined that if the QGA evolution remains in a certain state for more than half of the maximum generation, the evolution will be terminated automatically.
In summary, the QGA process is described in Fig. 1.
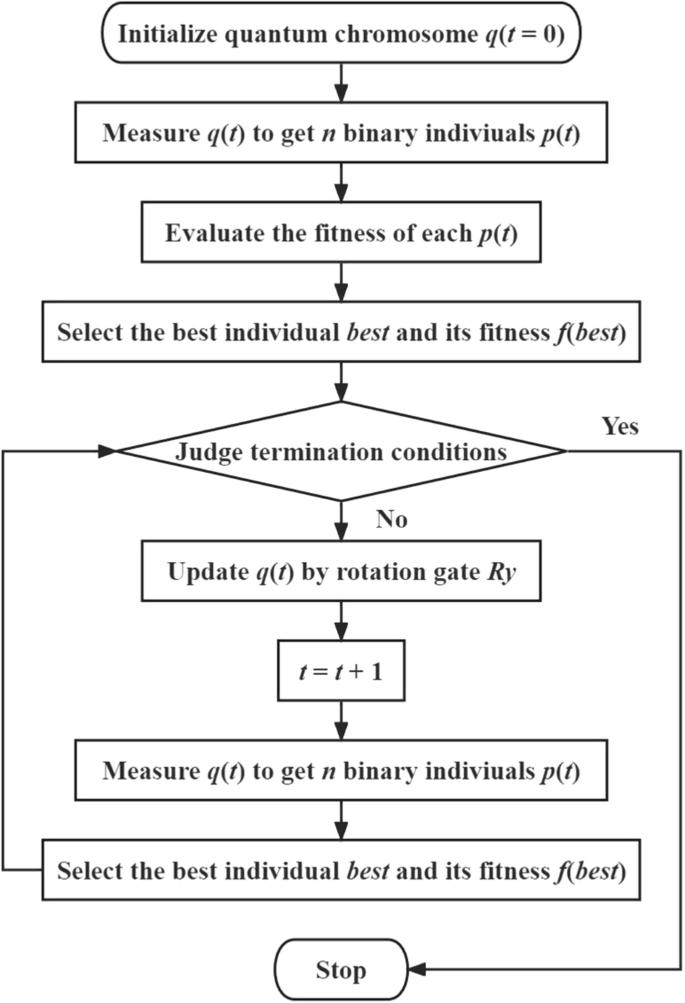
A quantum chromosome is first initialized, followed by the measurement and fitness evaluation of measured individuals. The best individual is selected from all the measurements, and its genetic information is used to guide the evolution of the quantum chromosome. The process repeats until the termination conditions are satisfied.
Optimization of PML TRC
We consider the design of an N layer PML for TRC (as shown in Fig. 2a). The thickness of designed PML is 1200 nm in total. Each layer of the PML structure can be one of four candidate materials: silicon dioxide (SiO2), silicon nitride (Si3N4), titanium dioxide (TiO2), or aluminum oxide (Al2O3), and each material is assigned one of the combinations of two binary labels (00 = SiO2, 01 = Si3N4, 10 = TiO2, 11 = Al2O3). The concatenation of these binary labels in order gives a 2N-long vector representing the structure. The optimization of PML structures is to minimize the FOM. The perfect PML can block all UV and IR light while allowing all visible light to transmit through. The proposed QGA, as an optimizer, is utilized to perform the optimization. As a comparison, we have also used CGA and QA for the same optimization problem. The details of QA can be found in Supplementary Information, Section 3.

a The schematic structure of the PML in the TRC. With proper binary embedding for candidate materials, the PML can be mapped into a binary vector. b The workflow of active learning iteration between RF, QGA and TMM.
Fig. 2(b) shows the schematic of the QGA-facilitated optimization algorithm proposed for PML optimization. The algorithm is based on active learning scheme with iterations of random forest (RF) training, QGA optimization, and TMM calculations. The details of the algorithm can be found in Method section.
We first take N = 6 as a benchmark study to test our algorithm, for which we can afford performing an exhaustive search by calculating the optical properties using the transfer matrix method (TMM), which is the most efficient method to calculate optical characteristics of PML structures and evaluate the FOM of every one of all the 46 = 4096 possible structures. The optimal structure, denoted as [10 10 00 10 01 11], is identified with a FOM of 1.7713 from this brute force exhaustive search. We then used our QGA-facilitated optimization to solve the same N = 6 problem. The QGA-facilitated optimization is implemented with an initial training set with the amount of data of m = 25 and a maximum iteration number of 10. In each generation, the quantum chromosome undergoes 25 measurements, and fitness evaluations are performed on these measurements using the RF surrogate model to discern the evolution direction of the quantum chromosome. An adaptive rotating angle, as defined in Eq. 4, decays from the upper to the lower bounds of 0.1π and 0.01π, respectively. Throughout the evolution process, the mutation rate is maintained at 0.001. The QGA terminates after 100 generations or if it reaches a converged state before that. Fig. 3 shows the evolution of FOM in the QGA optimization. The blue curve, orange curve and green curve represent the best FOM in the current generation, the average FOM in the current generation and the best FOM of all time, respectively. The x-axis is the step in the entire optimization, and each iteration of the active learning has 100 steps (correspond to 100 generations in QGA). As the figure shows, in each iteration, the FOM decays to a converged value, and the next iteration starts with a newly initialized quantum chromosome which partially include the information from the last iteration (the details of the quantum chromosomes initialization is shown by Eq. 6). After only 5 iterations, the FOM has successfully converged to 1.7713, which is consistent with the solution obtained from the exhaustive search. Compared with the 4096 TMM calculations required by the brute force exhaustive search, QGA only requires ~125 TMM calculations (details in the Methods section) in 5 active learning iterations to label the solution of each iteration before getting the global optima. This benchmark test indicates the effectiveness and efficiency of our QGA-facilitated active learning optimization scheme.

The blue curve, orange curve and green curve represent the best FOM in the current generation, the average FOM in the current generation and the best FOM of all time, respectively. In each iteration of our active learning scheme, there are 100 generations for the QGA.
The optimization is subsequently carried out for structures with N = 8, 10, 16, and 20. Optimizing structures with higher N demands a larger population size and an increased number of generations in QGA. In addition, a larger initial dataset may also be needed to start the iterations efficiently. The parameters for the optimization are detailed in the Supplementary Information, section 2. Fig. 4 shows the evolution of the best FOM of all time for N = 8, 10, 16 and 20, and the long-term convergence states in the high dimensional cases are not shown to highlight the FOM evolution at the early stage. For low dimensional cases (N = 8 and 10), our algorithm can discover accurate ground state obtained from exhaustive search faster than CGA-facilitated optimizations. For higher dimensional problems (such as N = 16), our QGA algorithm can converge to the same structure as QA-facilitated optimization (using a real quantum annealer, D-Wave) within 7 iterations (under 5000 generations in total), while CGA start to fail obtaining a comparable result with QA. For the problem with N = 20, both CGA and QGA algorithms cannot find the structure that is as good as QA finds. That is because the extremely large dimension of the search space requires an extremely large number of measurements in each generation to explore, which is prohibitively computationally expensive using a classical computer. Theoretically, the randomness introduced by quantum measurements, given a sufficient number of measurements, will guide the algorithm to explore the search space. The process involved in finding a local optimum, escaping from it, and then identifying a better solution, ultimately converging to a global optimum or a proper local optimum, can be very computationally intensive and time-consuming when using a classical computer to mimic quantum operations50. Especially when the dimension of the problem increases, the required measurement of quantum chromosomes and the fitness evaluation of each measurement result will be the bottleneck of computational efficiency and will also be the decisive factor in whether the algorithm can converge to the optimal solution. To improve the performance of the algorithm on higher-dimensional problems, future work can focus on accelerating the measurement of quantum states, so that most of the evolution operations of QGA can be migrated to real quantum devices, greatly reducing the amount of computation undertaken by classical computers during the optimization, thereby improving the ability of QGA algorithm on high-dimensional problems. Nevertheless, due to the inherent quantum properties, QGA still outperforms CGA on both converging speed and exploring ability.

Panel (a) ~ (d) represent the results of N = 8, 10, 16 and 20, respectively. The solid lines represent the average values from 5 multiple independent numerical experiments. The shadow regions represent the range of the best FOM from different trials. The horizontal green dash lines in the plots are the ground truth from exhaustive search (for N = 8 and 10) or the best solution from QA-assisted optimization algorithm (for N = 16 and 20).
The thicknesses of all the PML TRCs discussed above are fixed at 1200 nm. However, the overall thickness of the PML structures is also important for TRC performance. We explore how varying the total thickness of the PML structure affects its performance. Specifically, 16-layer PML structures with different overall thicknesses (1200 nm, 1000 nm, and 800 nm) are optimized using the proposed algorithm. Fig. 5 shows the evolution of the best FOM in QGA for the three different PML TRCs. QA-assisted optimizations are used to benchmark optimized results for QGA-facilitated optimization. For all the three systems, out QGA-facilitated algorithm can still converge to the same solution as QA-facilitated algorithm. The effect of PML thickness on TRC performance is not monotonic. Compared to the 1200 nm structure, both the 1000 nm and 800 nm structures show better performance, with the 1000 nm structure outperforming the 800 nm structure. This makes thickness a key variable in the design of TRC materials. However, since thickness is a continuous variable, it cannot be directly optimized using QA. Therefore, developing an efficient discretization method for continuous variables such as thickness will become an important factor in applying quantum algorithms to material design. In future work, we will focus on developing discretization methods to enable the application of quantum algorithms for material design.

The solid lines and shadow represent the average values and the range of the best FOM from 5 multiple independent numerical experiments. Dash lines represent the results from QA-assisted optimization algorithm.
Computational efficiency analysis
One crucial metric for evaluating the efficiency of an algorithm is its computational cost. In the context of the PML optimization using active learning, the total number of TMM calculations, which is the rate-limiting step in the iteration, serves as a key indicator of this cost. When optimizing an N-layered structure, an exhaustive search approach would necessitate 4 N TMM calculations to explore all possible solutions before identifying the true global optimum.
Fig. 6 shows the relationship between the number of required fitness evaluations by TMM calculations and the number of layers in the design by using exhaustive search, QGA and QA. For QGA, only the cases that found the global optima are counted in comparison. Note, the y-axis is plotted on a log10 scale. The efficacy of our QGA-facilitated and QA-facilitated optimization is highlighted by their substantially reduced need for TMM calculations as compared to exhaustive search methods. This advantage is further amplified by the high-performance nature of the RF model, which enables the max required TMM calculation by the QGA-facilitated optimization algorithm basically the same order of magnitude as the QA-assisted optimization algorithm, but during the optimizations, the QGA-facilitated algorithm requires even fewer TMM calculations as the it gradually converges to the optimal structure and producing repeated solutions in the labeling. This results in a significant alleviation of the burden traditionally associated with data acquisition, which is the TMM calculation in our case, but can be other physics-based modeling or experiments in other optimization tasks. This advantage is believed to be from the accuracy of the surrogate model, which is further discussed in the next section.

For QGA, we only take the cases that successfully converge with global optima (from exhaustive search for low dimensional cases) and QA results (for high dimensional cases). The numbers of TMM calculations in QGA-facilitated optimization are less than the max evaluation, which is the population size × iteration number.
Comparison between random forest (RF) and factorization machine (FM) model
Although the QGA’s global search capability is currently not as good as QA in the high dimension optimization cases, the superiority of the RF model over factorization machine (FM), which is the required surrogate for QA as it can be mapped into a QUBO formulation, affords our proposed QGA-facilitated optimization algorithm a more reliable searching landscape for high-dimensional problems. Fig. 7 provides a comparative analysis of the Rooted Mean Squared Error (RMSE) for FM and RF. Both are trained using TMM-calculated FOM data from of 8-layer, 10-layer, 16-layer, and 20-layer structures, with varying numbers of data points (25, 50, 75, and 100) randomly selected. 10 independent experiments have been performed and the standard errors of the mean are calculated as the error bars. Training is implemented with 5-fold cross-validation and Stochastic Gradient Descent (SGD), and RMSE is evaluated on a randomly selected test set. The results show that RF models outperform FM on the test sets. Moreover, as the data dimensionality increases, the advantages of RF become more apparent. From Fig. 7, especially in panels (c) and (d), it can be seen that the RF model trained with less data can achieve higher accuracy than the FM model trained with more data, which indicates that the RF model requires less data to achieve higher prediction accuracy than FM model, which should be the reason why fewer iterations are necessary in our QGA-facilitated optimization algorithm than the QA-assisted optimization.

Panel (a) ~ (d) show the comparisons for (a) N = 8, (b) N = 10, (c) N = 16, and (d) N = 20. RMSE is evaluated on the same test dataset for FM and RF models. The error bars are calculated from the results of 10 independent experiments.
To further confirm this hypothesis, the trained RF and FM models are subsequently employed as surrogate models for the QGA in optimizing PML structures with dimensions of N = 8 and 16. Fig. 8 illustrates the evolution curves of QGA when utilizing RF and FM as surrogate models with the same initialization. It can be observed that for the low-dimensional problem of N = 8, QGA always converges to the optimal structure regardless of the surrogate model employed, and the converging speed using RF is faster than FM. However, for the higher-dimensional scenario (N = 16), employing RF as the surrogate model enhances the speed of QGA’s convergence greatly. This substantiates the advantage of using RF as a more general surrogate model over FM.

a N = 8 and (b) N = 16. Solid lines and shadows represent average FOM evolution and range of multiple trials.
Energy Saving Analysis
Lastly, we estimated the benefit of the 16-layer and 20-layer TRC designed by our algorithm as a potential window material by calculating the energy it can save annually in the U.S. using EnergyPlus24,51. The annual energy saving over the surveyed U.S. cities is shown in Fig. 9a, b. On average, the application of the 16-layer TRC as a window material would yield an annual energy saving of 33.58 MJ/m2 over the surveyed locations. Even for the 20-layer TRC structure, despite not reaching the global minimum, can still contribute to an average annual energy saving of 26.03 MJ/m2. Fig. 9c, d show the energy savings for the top 15 energy consuming states in the U.S. For the hot states (e.g., Arizona, Nevada, and Hawaii), our designed 16-layer TRC can potentially save ~30% of the cooling energy compared to conventional windows. The same calculations have also been performed for 20-layer TRC, and an energy saving over 20% can be achieved. Fig. 9e shows the comparison between the transmitted irradiance through the ideal and our optimized 16-layer and 20-layer TRCs. The transmitted irradiance of the 16-layer structure has better alignment with the ideal TRC, showing better performance than the 20-layer structure.

Panel (a) and (b) show the estimated cooling energy saving across the U.S. by using the 16-layer and 20-layer TRC as the window material, respectively. The annual energy savings of the top 15 energy-consuming states over U.S. by applying (c) the 16-layer TRC and (d) the 20-layer TRC designed by our QGA-facilitated optimization. e The transmitted irradiance through the target ideal and our optimized 16-layer and 20-layer TRCs by QGA-facilitated active learning scheme.
Towards More Applications – Optimization of Optical Diodes
In addition to the application in the TRC design, our QGA-facilitated optimization algorithm can be applied to other material design problems. Here, we test the performance of our algorithm on designing metamaterials optical diodes. Nanophotonic structures that exhibit asymmetrical power (intensity) transmission can be considered optical diodes, following the concept of electrical or thermal diodes that have asymmetrical transport properties52,53,54. An optical diode permits the intensity of light to transmit in one direction (i.e., forward direction) but blocks it in the reverse direction (i.e., backward direction). The FOM of an optical diode can be defined as the difference between the forward (TF) and backward (TB) transmissivities (i.e., FOM = TF – TB)55, and a larger FOM indicates the better performance of the optical diode.
The stratified volume diffractive film composed of metal and dielectric materials can be considered as a system for optical diodes. Fig. 10a shows the schematic structure of the thin-film optical diode with a stratified volume diffractive film, in which it has a unit cell consisting of metallic gratings and a dielectric spacer. Fig. 10b shows the configuration of the unit cell, which is discretized with rectangular pixels, as proposed by Kim et al. in ref. [55]. The material selection of a pixel can be encoded into a binary digit as “0” for a dielectric or “1” for a metal medium. The pixelated metamaterial structure is then represented by a binary vector with a length of N. FOMs of the structures are calculated using the rigorous coupled-wave analysis (RCWA) method56. Here, we test our algorithm on two cases: wavelength λ = 600 nm (N = 40) and 800 nm (N = 32). Fig. 10c shows the evolution of the best FOM as a function of optimization steps for both cases. For these high dimensional optimization problems, although still limited by computational resources to find the same optimal structures as QA-assisted optimization algorithm found (0.8064 for λ = 600 nm, 0.8648 for λ = 800 nm), our algorithm can still lead the exploration of the design space towards the right direction within 50 iterations (the population sizes are 200 in both cases). The number of RCWA calculations in the QGA-facilitated algorithm is under 10,000 in both cases, which are in the same order of magnitude as the thousands of RCWA calculations needed for the QA-assisted algorithm. Comparing with CGA-facilitated optimization, our QGA-facilitated algorithm can still converge faster to better optimal structures, which has been already been shown in the TRC case.

a the thin-film optical diode with a stratified volume diffractive film for optimization and (b) the pixelated unit cell of the structure. c Evolution of FOM in QGA-facilitated algorithm for 600 nm and 800 nm wavelength. The dimensions of the binary vector are N = 40 and N = 32, respectively. The average FOM evolutions of the two cases in CGA-facilitated optimizations are compared with that in QGA-facilitated optimizations.
link




